TiDB集群上线运行一段时间,近期巡检的时候发现一个问题,集群中TiKV节点内存占用比较高,尤其在导入数据的时候,节点的内存会更高

下面我们就针对TiKV节点高的问题进行分析:
首先确认下TiKV节点配置如下:

问题排查:
1、登录到单个TiKV接节点,查看内存占用情况

2、确认节点的THP(内存大页)是否关闭
关闭透明大页(即 Transparent Huge Pages,缩写为 THP)。数据库的内存访问模式往往是稀疏的而非连续的。当高阶内存碎片化比较严重时,分配 THP 页面会出现较高的延迟。
$ cat /sys/kernel/mm/transparent_hugepage/enabled always madvise [never]
从查看结果看,内存大页是关闭的
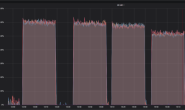
3、在 通过监控TiKV-Details RockDB面板确认是否是block size引起的,查看每一个TiKV节点的block size的内存占用都达到了最大设置10G

调整block size大小的配置,建议不超过机器内存的60%
调整参数,调整大小为7G,storage.block-cache.capacity: 7GB
$ tiup cluster edit-config tidb-prod001
调整完成之后,重启TiKV节点
$ tiup cluster reload tidb-prod001 -R tikv
重启完成后,查看内存占用情况
拓展:
TiKV的配置参数:
storage.block-cache 表示RocksDB 多个 CF 之间共享 block cache 的配置选项。当开启时,为每个 CF 单独配置的 block cache 将无效。
shared
是否开启共享 block cache。
默认值:true
capacity
共享 block cache 的大小。
默认值:系统总内存大小的 45%
单位:KB|MB|GB
为了提高读取性能以及减少对磁盘的读取,RocksDB 将存储在磁盘上的文件都按照一定大小切分成 block(默认是 64KB),读取 block 时先去内存中的 BlockCache 中查看该块数据是否存在,存在的话则可以直接从内存中读取而不必访问磁盘,可以理解为MySQL中的innodb buffer pool。
BlockCache 按照 LRU 算法淘汰低频访问的数据,TiKV 默认将系统总内存大小的 45% 用于 BlockCache,用户也可以自行修改 storage.block-cache.capacity 配置设置为合适的值,但是不建议超过系统总内存的 60%。
写入 RocksDB 中的数据会写入 MemTable,当一个 MemTable 的大小超过 128MB 时,会切换到一个新的 MemTable 来提供写入。TiKV 中一共有 2 个 RocksDB 实例,合计 4 个 ColumnFamily,每个 ColumnFamily 的单个 MemTable 大小限制是 128MB,最多允许 5 个 MemTable 存在,否则会阻塞前台写入,因此这部分占用的内存最多为 4 x 5 x 128MB = 2.5GB。这部分占用内存较少,不建议用户自行更改。