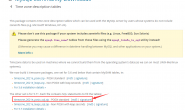
最近发现隔几天就会出现一台实例备份失败的情况,具体的报错信息如下所示
xtrabackup: error: log block numbers mismatch: xtrabackup: error: expected log block no. 172665700, but got no. 176859996 from the log file. xtrabackup: error: it looks like InnoDB log has wrapped around before xtrabackup could process all records due to either log copying being too slow, or log files being too small. xtrabackup: Error: xtrabackup_copy_logfile() failed.
原因分析
备份失败原因在xtrabackup的输出信息中已经有说明:log block numbers mismatch,大概的意思是说:XtraBackup在顺序拷贝完redo log末尾的数据后,重新从redo log的起始位置去拷贝时,发现起始位置的log block no.与刚才尾部的no.不连续。
expected log block no. 172665700, but got no. 176859996 from the log file.,本应该读取的redo 块是no. 172665700,但是只能获取到no. 176859996
读redo错误的原因:it looks like InnoDB log has wrapped around before xtrabackup could process all records due to either log copying being too slow,
要么xtrabackup读取redo的速度太慢了,或者redo 文件太小了,导致读取速度跟不上redo文件的切换速度,在读取之前,相应的redo块已经被覆盖了。
1、检查redo log相关的系统变量:
innodb_log_file_size=1073741824 innodb_log_files_in_group=2
从以上设置可以看出,设置的redo log大小是2 * 1024M,文件大小设置的一般情况可以满足需求。
2、检查实例在备份时间左右的负载,发现实例的整体负载都正常,没发现异常;
3、此时又想起了一件事,最近将8个分布式集群的的配置方式调整成了全量备份,并且远程备份传输;
检查备份机的监控,发现备份机的压力比较大,所以出现网络带宽小而导致拥堵的情况
解决方法
由于innodb_log_file_size变量不能动态更改,暂时也不能重启数据库更改变量值,并且备份失败的原因也不在redo大小设置的问题。所以将XtraBackup的开始时间推迟了一段时间,以错开集群备份时的IO高峰期。
备份计划推迟后,经过一周的观察,该实例的备份没有再次出现错误。