我们都知道,在关系型数据库中,索引的存在是非常重要的,但是不合理的索引反而会影响到业务的性能,那怎么才能合理的设计索引也是业务高效访问数据库需要考虑的?那如何才能评估索引创建的合理呢?今天我们给出其中一个评估指标:Cardinality
在MySQL数据库中,如何查看表的索引情况呢?
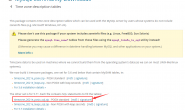
执行show index from tb_name;命令即可;如下所示:
mysql >show index from sbtest1\G
*************************** 1. row ***************************
Table: sbtest1
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 48229276
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: sbtest1
Non_unique: 1
Key_name: k_1
Seq_in_index: 1
Column_name: k
Collation: A
Cardinality: 9172199
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
2 rows in set (0.01 sec)
那什么是Cardinality值?
官方文档解释:
An estimate of the number of unique values in the index. To update this number, run ANALYZE TABLE or (for MyISAM tables) myisamchk -a.
Cardinality is counted based on statistics stored as integers, so the value is not necessarily exact even for small tables. The higher the cardinality, the greater the chance that MySQL uses the index when doing joins.
并不是在所有的查询条件中出现的列都需要添加索引。对于什么时候添加B+树索引,一般的经验是,在访问表中很少一部分数据时使用B+树索引才有意义。例如,对于性别字段、地区字段、类型字段、状态字段,它们的可取值范围很小,成为低选择性的列。如:
select * from student where sex=’F’
按照性别查找时,可取值的范围一般是“M”和“F”。因此上述sql语句得到的结果可能是该表的50%数据,这个时候添加B+索引没有必要。但如果某个字段的取值范围很广,几乎没有重复,我们称之为高选择性,添加B+树索引很合适。
Cardinality表示索引的选择性。建立索引的前提是列中的数据是高选择性的。MySQL如何来统计Cardinality信息呢?MySQL数据库中有各种不同的存储引擎,而每种存储引擎对于B+树的实现方式各不相同,所以对于Cardinality的统计是放在存储引擎层进行的。
我们需要知道,在生产环境中,索引的更新操作可能是非常频繁的。如果每次索引在发生更新操作时,就对其进行Cardinality值的统计,那么将会给数据库带来很大的负担。如果一张表的数据非常大,假设有上百G,那么统计一次Cardinality信息所需要的时间可能非常长。在生产环境中,也是不能接受的。因此,数据库对于Cardinality的统计是通过采样(Sample)的方法来完成的。
那么什么时候会更新Cardinality值呢?以及这个值是如何得到的?
更新Cardinality发生在insert和update两个操作中。但是不是每次表中的索引发生insert和update的时候就去更新Cardinality信息。InnoDB存储引擎内部对更新Cardinality信息的策略为:
1) 表中1/16的数据已发生过变化
2) stat_modified_counter>2 000 000 000 (stat_modified_counter是innodb存储引擎中的一个计数器)
第一种策略为自从上一次统计过Cardinality信息之后,表中1/16的数据已经发生过变化,此时就要触发更新Cardinality信息了。
第二种策略考虑到一种情况,如果对表中某一行或者多行的数据频繁地进行更新操作,但是表中的记录数没有增加,发生变化的数据还是这一行或者多行。那么很显然,第一种更新策略无法适用这种情况。这个计数器stat_modified_counter大于2 000 000 000时,同样需要更新Cardinality的信息。
默认Innodb存储引擎对8个叶子节点进行采样。受参数innodb_stats_sample_pages影响。